Karpenter in production: right-sizing в масштабе
Как Salesforce сократили 70% стоимости кластеров на Karpenter — 3 ловушки и 4-шаговый rollout на 1000+ кластерах.
Виктор Ведмич · 6 мин чтения
Salesforce запускает Karpenter на более чем 1000 production-кластерах Kubernetes. Переход с Cluster Autoscaler сократил стоимость кластеров на 70% и снизил время provision до 60 секунд. Вот что они выяснили — и три ловушки, с которыми сталкивается большинство команд, прежде чем достичь этих цифр.
Почему Karpenter отличается
Cluster Autoscaler масштабирует node groups. Karpenter масштабирует ноды.
Звучит тривиально, пока не понимаешь, что это значит: CA требует, чтобы вы предварительно определили типы инстансов в node groups, прежде чем autoscaling сможет выбрать один. Karpenter смотрит на требования pending-подов — CPU, память, архитектуру, availability zone, instance family — и provision то, что подходит, без создания дюжины node groups.
Результат: более быстрый provisioning (менее 60 секунд против 3-5 минут), лучший bin-packing (Karpenter автоматически консолидирует недоиспользуемые ноды) и прямая интеграция с cloud-провайдером (без polling lag — Karpenter следит за Kubernetes API server и действует немедленно).
Этот путь — kubectl через API server, etcd и scheduler, в kubelet, затем работающие поды — именно то, что Karpenter ускоряет. Cluster Autoscaler добавляет polling-цикл между «pod pending» и «запросом новой ноды»; Karpenter следит за API напрямую.
Но скорость и гибкость приходят с риском. Если вы не ограничите Karpenter, он provision инстанс с 96 ядрами для 3 маленьких подов. Я видел, как staging-счета удваивались за ночь, потому что команда забыла установить NodePool limits. Давайте пройдёмся по трём ловушкам.
Ловушка 1 — Скорость provisioning приводит к overscaling

Karpenter provision за 60 секунд. Cluster Autoscaler — за 3-5 минут.
Миф о скорости — вера в то, что быстрее всегда лучше. Вот что происходит на самом деле: deployment создаёт 10 pending-подов. Karpenter видит их, выбирает первый тип инстанса, который вместит все 10 подов на одной ноде. Если ваши requirements не ограничены, этот инстанс может быть c6i.32xlarge (128 vCPU, $5.44/час on-demand).
Ловушка закрывается, когда эти 10 подов нужны только 2 vCPU каждому. Вы заплатили за 128 vCPU, чтобы запустить 20 vCPU реальной нагрузки.
Исправление: NodePool limits и requirements. Установите ceiling для CPU — limits.cpu: 64 означает, что Karpenter никогда не provision ноду больше 64 vCPU. Ограничьте instance families — requirements: [{ key: "karpenter.k8s.aws/instance-family", operator: In, values: ["m7i", "m7a"] }] означает, что Karpenter рассматривает только general-purpose типы инстансов, а не compute-optimized монстров.
Я рекомендую начинать со Spot-инстансов по умолчанию и on-demand fallback. Блок requirements в Karpenter позволяет сказать “Spot сначала, on-demand если Spot недоступен в течение 60 секунд”. Это само по себе снижает стоимость на 70% по сравнению с on-demand-only, с минимальным риском interruption, если вы правильно настроили Pod Disruption Budgets (подробнее об этом в ловушке 3).
Ловушка 2 — Запуск Cluster Autoscaler и Karpenter одновременно

Cluster Autoscaler масштабирует ноды вверх. Karpenter консолидирует их вниз. Оба смотрят на одни и те же поды.
Если запустить оба, получите oscillation: CA добавляет ноду node group в 10:00. Karpenter видит недоиспользуемые ноды в 10:02 и drain CA-ноду. Поды переезжают на Karpenter-управляемую ноду. CA снова видит pending-поды и масштабирует node group обратно в 10:05. Повторить.
Я дебажил это у клиента с 200 EKS-кластерами. Их мониторинг показывал 30-50 замен нод в час. Поды были здоровы, но churn был достаточно высоким, чтобы вызывать false positive в их anomaly detection.
Исправление: разделить ownership. Cluster Autoscaler владеет system node groups (kube-system, logging, monitoring — всё, что должно оставаться на предсказуемых, долгоживущих on-demand нодах). Karpenter владеет всем остальным.

Технически это делается через taints и labels. Ваша system node group получает node-role.kubernetes.io/system=true:NoSchedule. kube-system поды получают соответствующий toleration. Всё остальное попадает на Karpenter-управляемые ноды. CA и Karpenter теперь работают на непересекающихся множествах — больше никакого race.
Salesforce использует этот паттерн на всех 1000+ кластерах. CA масштабирует их stateful workloads и system-компоненты. Karpenter обрабатывает stateless fleet. Чистое разделение, нулевой oscillation.
Ловушка 3 — Karpenter будет churn production-поды во время пикового трафика, если вы его не остановите

По умолчанию Karpenter консолидирует каждый раз, когда находит более дешёвую упаковку. Включая business hours.
Вот кошмарный сценарий: ваш трафик пикует в 14:00. Karpenter видит две ноды, каждая на 40% utilization. Он понимает, что может упаковать поды обеих нод на одну ноду, экономя $2/час. Он drain ноду A, перемещает поды на ноду B. Рестарт пода занимает 15 секунд. Ваши пользователи видят 15 секунд 500 ошибок, потому что вы не установили PodDisruptionBudget.
Даже с PDB consolidation churn — проблема. Дефолтный Karpenter consolidateAfter: 30s означает, что он начинает drain нод через 30 секунд после того, как они становятся underutilized. В динамической нагрузке это слишком агрессивно.
Исправление: disruption budgets и consolidation schedules. Snippet NodePool из carousel показывает паттерн:
spec:
disruption:
consolidationPolicy: WhenUnderutilized
consolidateAfter: 30s
budgets:
# No churn Mon-Fri 09-18 UTC
- schedule: "0 9 * * 1-5"
duration: 9h
nodes: "0"Этот schedule говорит: понедельник-пятница, с 9 до 18 UTC, не drain никакие ноды (nodes: "0"). Karpenter всё ещё будет provision ноды, если поды pending, но не будет консолидировать существующие ноды в business hours.
Комбинируйте это с per-application PodDisruptionBudgets:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: frontend-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: frontendЭтот PDB говорит: минимум 2 frontend-пода должны оставаться запущенными всегда. Если Karpenter пытается drain ноду, он должен уважать PDB. Если drain нарушит PDB, drain блокируется.
Я рекомендую начинать с permissive consolidateAfter: 5m и business-hours disruption budget. Мониторьте pod restart rate неделю. Если не видите churn в business hours и приемлемый churn ночью, ужмите consolidateAfter до 2m. Если видите слишком много churn, расширьте business-hours окно.
4-шаговый production rollout
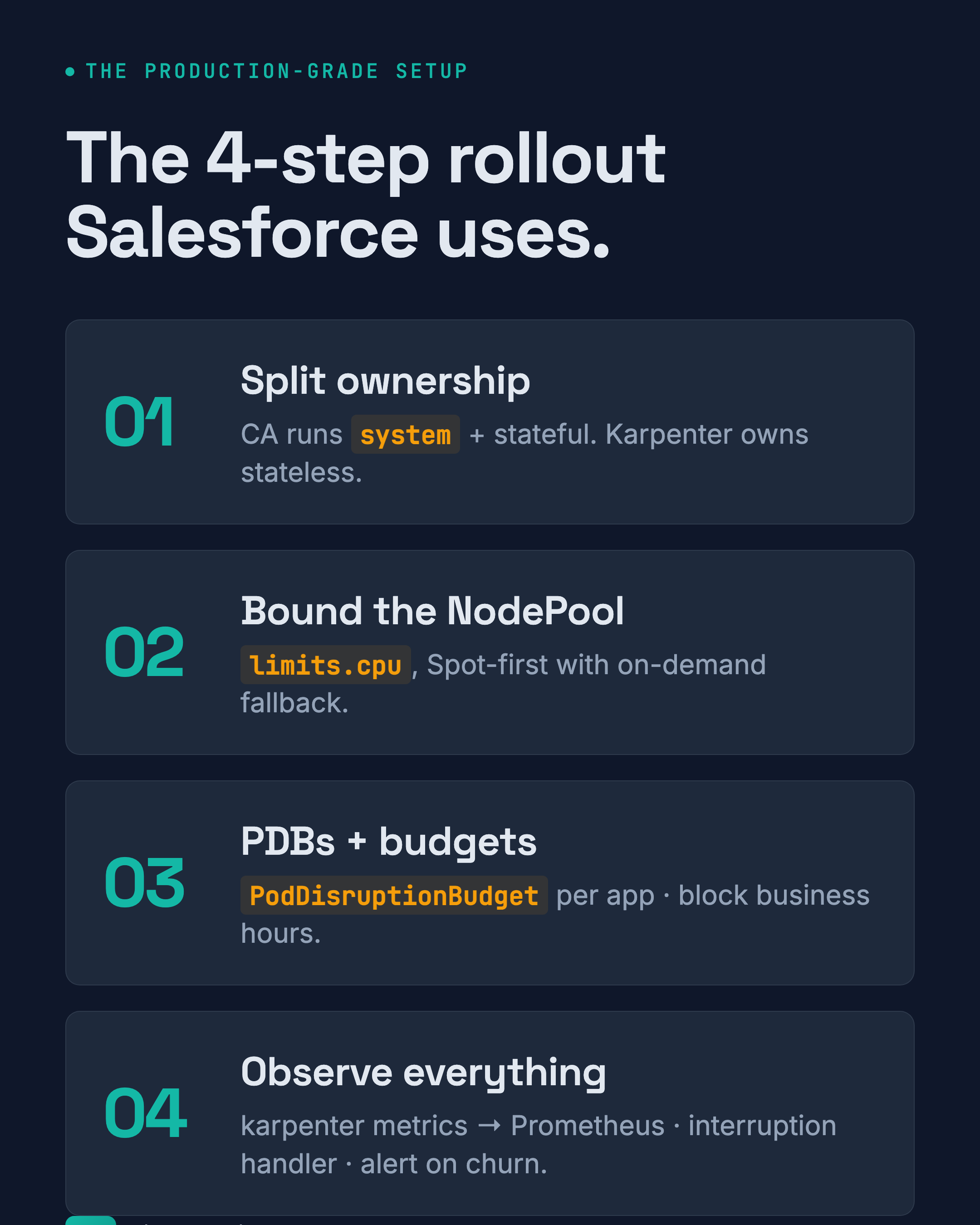
Паттерн rollout Salesforce — тот, который я рекомендую каждому клиенту:
Шаг 1: Разделить ownership. Cluster Autoscaler запускает system и stateful workloads (taints + tolerations). Karpenter владеет stateless. Без overlap.
Шаг 2: Ограничить NodePool. Установите limits.cpu, ограничьте instance families, по умолчанию Spot с on-demand fallback. Не позволяйте Karpenter provision без ограничений.
Шаг 3: PDB и budgets. Каждое приложение получает PodDisruptionBudget. Каждый NodePool получает disruption budget, блокирующий consolidation в business hours.
Шаг 4: Мониторить всё. Karpenter экспортирует Prometheus metrics — karpenter_nodes_created, karpenter_pods_startup_duration, karpenter_interruption_actions_performed. Алерт на node churn rate (rate(karpenter_nodes_terminated_total[5m]) > 5 означает, что вы churn больше 5 нод за 5 минут — исследуйте).
Подключите Karpenter metrics в ваш существующий Prometheus setup. Используйте AWS Node Termination Handler для graceful drain Spot-нод, когда AWS отправляет 2-минутное interruption notice. Следите за pod eviction rate — если он spike, ваши PDB слишком loose.
Начните с малого, измеряйте, масштабируйте
Если вы переходите с Cluster Autoscaler на Karpenter, начните с одного некритичного NodePool. Выберите низкотрафиковое приложение — внутренние инструменты, staging environments, batch jobs. Измеряйте provisioning latency, стоимость за под и eviction rate две недели, прежде чем раскатывать на production fleet.
Цифры Salesforce — 70% снижение стоимости, 1000+ кластеров, provision за 60 секунд — реальны. Но они не начинали с этого. Они начали с одного кластера, одного NodePool и двух недель метрик. Затем масштабировали.
Karpenter быстрее, дешевле и гибче, чем Cluster Autoscaler. Но скорость без guardrails — биллинговая катастрофа. Установите limits, разделите ownership, используйте PDB и следите за метриками. Экономия стоит того.
Связанные материалы
- LinkedIn-карусель: Karpenter на 1000 кластерах — 3 ловушки до того, как вы сократите стоимость — источник для этой статьи
- AWS Summit Warsaw 2026 (DOP202): Integrated AI Agents & Code Assistants with MCP & AWS — предстоящий доклад, 2026-05-06